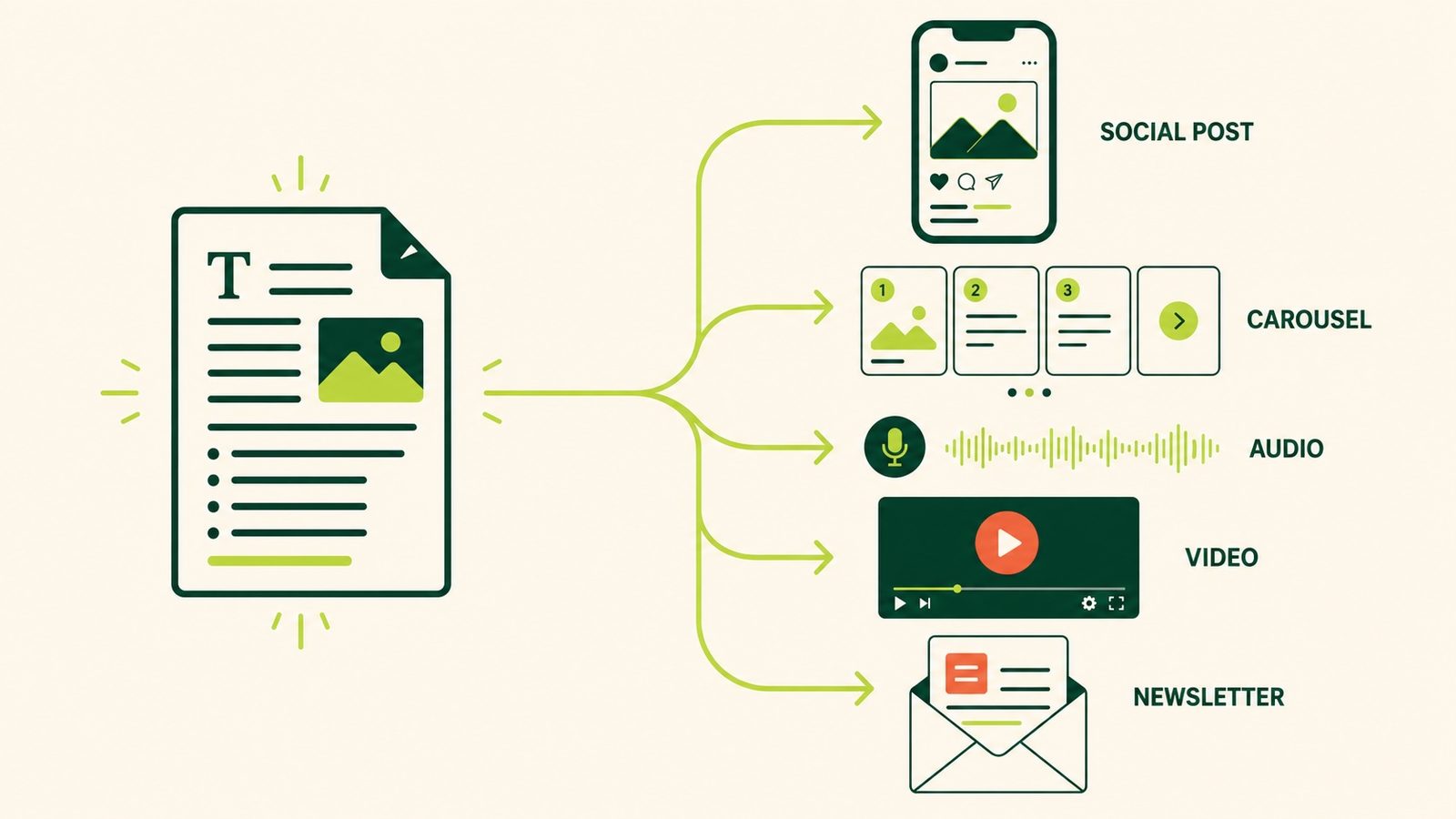
TL;DR: Google does not penalise AI content. Google penalises content with zero information gain, and unedited AI content almost always has zero information gain because it produces a statistical average of what already exists online. The March 2026 core update made information gain one of the dominant ranking signals. Sites that mass-published AI content without adding original data, lived experience, or editorial perspective saw traffic drops of 60–90%. The fix is not to avoid AI. The fix is to use AI for scaffolding and add the part only you can provide: the specific detail, the original data point, the defensible position that comes from having actually done the thing you are writing about.
How we researched this: This article draws on Google's official Search Central guidance on AI content, the Rankability study of 487 search results, a 16-month tracking study of 4,200 articles comparing AI and human content performance, Digital Applied's analysis of the March 2026 core update, published enforcement case studies (including Casual, TailRide, and FreshersLive), and observable ranking patterns across B2B content marketing verticals. Every statistic is attributed to its source.
The pattern plays out the same way across dozens of content operations. A team does everything by the book. Keyword research. Competitive gap analysis. A content calendar targeting 40 articles in 90 days, each drafted with Claude, edited for clarity, optimised for on-page signals, and published on a technically sound site with decent domain authority.
For the first six weeks the strategy worked. Organic impressions climbed. Several pages reached page one for their target keywords. The content director reported a 3x increase in organic traffic during the Q1 review and projected hitting the annual traffic goal by July.
Then the March 2026 core update rolled out over 12 days, starting March 27 and completing April 8. Nearly 80% of URLs in the top three positions changed their rankings across the affected queries, according to SEMrush Sensor data that recorded a volatility peak of 9.5 out of 10.
Of the team's 40 articles, 32 dropped off page one. Twelve disappeared from the top 50 entirely.
The content director's first instinct was the same one circulating in every marketing Slack channel, X thread, and SEO forum: Google is penalising AI content. That instinct is wrong, and understanding why it is wrong is the only path to recovery.

The Myth vs. the Evidence
Google's position on AI-generated content is not ambiguous. The company's Search Central documentation states that its systems evaluate content quality "rather than how content is produced." This is not a vague platitude buried in a help page. It is the operating principle behind how ranking decisions are made.
What Google does target is specific: scaled content abuse. The spam policy defines this as using automation to generate many pages without adding value. The keyword is value, not automation. A publisher who uses AI to draft a page and then adds original research, specific expertise, and editorial judgment has not violated any policy. A publisher who uses AI to produce 500 pages of keyword-targeted summaries with no original contribution has created exactly the kind of content the helpful content system was built to demote.
The enforcement record confirms the distinction. Casual, a site that published approximately 1,800 AI-generated articles, was completely deindexed. TailRide published 22,000 machine-generated pages and saw traffic drop to zero. FreshersLive received a pure spam manual action. In every documented case, the sites had one thing in common: volume without substance. Not AI use. Volume without substance.
The Rankability study of 487 Google search results found that 83% of top-ranking results were human-generated content. That sounds damning for AI until you look at what the AI content in the study typically lacked: original data, cited sources, specific examples, and editorial perspective. A 16-month tracking study of 4,200 articles found that pure AI content ranked 23% lower on average than human-written articles, but AI-drafted content with substantive human editing performed within 4% of fully human-written content on median ranking position.
The gap is not between AI and human. The gap is between content that adds something new and content that does not.
Why AI Content All Looks the Same
Consider a keyword like "best project management tools for remote teams." Ask Claude, ChatGPT, Gemini, or any comparable model to write a comprehensive article on this topic. You will get a structurally competent piece that covers the same 8–10 tools in roughly the same order of popularity, describes the same features, makes the same general recommendations, and arrives at the same conclusion: the best tool depends on your team's specific needs.
Now imagine 50 content teams doing this simultaneously. Each produces a minor variation on the same underlying synthesis. The tools named are the same because the training data reflects the same market reality. The feature descriptions are similar because the facts are the same. The recommendations converge because the model produces a probability-weighted average of existing opinion.
This is the statistical convergence problem, and it is the single most important concept for anyone using AI in content marketing to understand.
Large language models generate text by predicting the most probable next token given the context. When the context is "write about best project management tools," the most probable output is a summary of the consensus view that already exists across millions of web pages. The model does not have proprietary experience with these tools. It does not have an opinion about which one fails in specific edge cases. It does not know which features break under specific conditions, or which integrations fail silently after a platform update, because that level of operational detail is not represented at sufficient frequency in its training data.
The result is content that is correct, competent, and completely interchangeable with every other AI-generated article on the same keyword.
You can test this yourself. Take any competitive B2B keyword. Generate articles on it with three different models. Compare the outputs side by side. The headings will differ slightly. The phrasing will vary. The underlying information will be nearly identical: the same tools, the same features, the same recommendations, the same equivocating conclusion. Now search that keyword and read the top five results written by humans who actually use the tools. The difference is immediate. One will mention a bug in the latest version. Another will describe a specific client implementation that failed. A third will take a strong position on which tool to avoid, with a reason that clearly comes from personal frustration rather than training data.
That specificity is what the model cannot produce. And it is what Google's ranking systems now actively reward.
Google does not need to detect that AI wrote your content. Its algorithms detect that your page contains nothing they have not already indexed 50 times over.
The Information Gain Test
Google patented a system for scoring what it calls information gain: the measure of how much new, substantive knowledge a page provides beyond what a user has already encountered on other pages about the same topic. If you read the current top five results for a keyword and then read a sixth page that covers the same points with different phrasing, the sixth page has near-zero information gain. It told you nothing you did not already know.
After the March 2026 core update, information gain moved from a secondary signal to one of the dominant content-quality evaluators. Digital Applied's analysis of the update found that sites publishing proprietary data, first-hand case studies, and experience-backed content saw ranking gains of 15–25%. Sites relying on AI-generated content published without expert review experienced visibility declines of 30–50%. Affiliate roundup sites were hit hardest, with up to 71% experiencing traffic declines.
The question every piece of content must answer before publication is simple: what does this article contain that cannot be found in any other article on this topic?
If the answer is "better writing" or "more comprehensive coverage" or "updated tool names," those are not information gain. Better writing is a presentation improvement. More comprehensive coverage is a length improvement. Updated tool names are a freshness improvement. None of them add new knowledge.
Information gain comes from a narrower set of sources. Original data you collected: a survey of your customers, a benchmark you ran, a metric you tracked over time. Specific experience you had: the tool that broke in a specific way, the workflow that failed before it succeeded, the client conversation that changed your approach. A defensible position you hold: not "both options have pros and cons" but "Option A is better for companies under 50 people and here is the specific reason, based on what we observed across 12 client implementations."
Each of those sources produces content that a model cannot generate from training data alone. Each of them creates something Google's information gain scoring can identify as novel.
What E-E-A-T's "Experience" Actually Means
Google added "Experience" to E-A-T in late 2022, creating the E-E-A-T framework that now underpins content quality evaluation. The Experience component is Google's algorithmic proxy for a question that matters more than any other in 2026: has this person actually done the thing they are writing about?
Experience signals are specific, first-person-observable details that language models cannot produce. They are the difference between content that summarises a topic and content that demonstrates direct involvement with it.
Here is what Experience looks like in practice.
Generic AI output: "Surfer SEO is a useful tool for content optimisation that helps writers create SEO-friendly content."
Content with Experience signal: "Surfer SEO's Content Editor scored this draft at 67 out of 100. After we added three original screenshots and replaced the AI-generated tool descriptions with notes from our own testing, the score dropped to 54. The page ranked #3 within six weeks. Surfer's score correlates with keyword density and structural similarity to existing top results. It does not measure originality, which means optimising for its score can actively work against information gain."
The second version contains detail that could only come from someone who has used the tool, tracked the outcome, and reflected on the discrepancy between the tool's recommendation and the real-world result. No model can hallucinate this level of specificity with accuracy.
Four more signals that distinguish Experience from generic coverage:
Failure documentation. "The first version of this workflow took longer than doing it manually because we over-prompted at the research stage, generating 4,000 words of synthesis that we then had to read, evaluate, and mostly discard." Failure detail is a strong Experience signal because models rarely generate it. Training data over-represents success narratives.
Named outcomes with numbers. "This approach increased organic traffic to our product comparison cluster by 34% over 90 days, measured in Google Search Console against the same period in the prior quarter." Specific, verifiable metrics demonstrate direct involvement.
Process friction. "We tried publishing AI-drafted articles with a single editing pass for three months. The pages that ranked had one thing in common: the editor had rewritten the introduction and conclusion entirely, replacing the AI's hedged positioning with a clear claim. The pages that did not rank were the ones where the editor only fixed grammar and formatting." Process detail reveals what actually happened, not what should theoretically work.
Contextual judgment. "Most guides recommend A/B testing headlines for SEO content. In practice, this adds two weeks to the publication cycle for a marginal improvement on pages that rank based on content depth, not click-through rate. We stopped A/B testing headlines for informational content and reallocated that time to adding original screenshots and data tables." A recommendation to stop doing something most guides recommend is a strong signal that the author has tested the conventional wisdom and found it wanting.
The Editorial Layer That Makes the Difference
The content teams that rank well with AI-assisted workflows share one structural decision: they budget time for the editorial layer that adds information gain. They treat the AI draft as raw material, not as a finished product that needs polish.
Five specific editorial steps separate content that ranks from content that disappears after the next core update.
Add original data, even at small scale. You do not need a 10,000-respondent survey. A poll of 20 customers, a tracked metric from your own analytics, a before-and-after screenshot from a tool you tested. The brand marketer in our recent profile did not conduct formal research. She tracked her own outputs: how long competitive analysis took before and after AI adoption, how many revision cycles her briefs required, what her team's content velocity looked like quarter over quarter. That data was hers alone. No model could replicate it.
Insert the specific detail that requires having done the thing. The version number. The exact error message. The name of the feature that does not work as documented. The workaround you discovered. These details are invisible to someone summarising a topic from secondary sources. They are immediately recognisable to someone who has lived the experience.
Take a defensible position. The greatest weakness of AI-generated content is its reflexive even-handedness. "On one hand... on the other hand... ultimately, it depends on your needs." This is not analysis. It is abdication. Every article that ranks for a competitive keyword in 2026 takes a position and defends it with evidence. Not controversy for its own sake. A perspective grounded in experience that gives the reader something to agree with, disagree with, or think about. The absence of perspective is the absence of information gain.
Cut the filler. AI models pad content to reach word count. They restate conclusions at the end of sections. They add transitional paragraphs that move the reader from one heading to the next without conveying new information. Every sentence that restates what the paragraph above already said is a sentence that reduces your information density and signals to both readers and algorithms that this content is not worth the space it occupies.
Write the conclusion before the introduction. If you draft the conclusion first, you force yourself to articulate the article's core claim before the supporting arguments have a chance to soften it. Most AI-drafted content arrives at a weak conclusion because the model follows the argument rather than leading with one. Start with the position. Then build the case. The resulting piece has a coherent editorial spine that readers and search algorithms both recognise as distinct from the weighted average.
A Realistic Workflow
The goal is not to eliminate AI from the content process. The goal is to use AI for the parts it handles well and reserve human judgment for the parts it cannot.
Research synthesis. AI excels at this. Feed a model your target keyword, the top five ranking pages, and your competitor landscape. Ask it to identify the consensus view: what does everyone say? What points do all the top results cover? This gives you the baseline. The baseline is the thing your content must go beyond, not replicate.
Structural outlining. AI produces competent outlines. Use them as starting points, then restructure based on your editorial position. If your angle is that the conventional wisdom about headline A/B testing is wrong, the structure needs to present the conventional view, challenge it with your evidence, and arrive at your recommendation. That narrative arc requires editorial judgment. The outline is just the scaffolding.
First draft. AI drafts are useful for getting past the blank page. Accept that you will rewrite 40–60% of the draft if you want the piece to rank. The sections that survive will be factual summaries where accuracy matters more than originality: definitions, background context, tool feature descriptions. The sections that need rewriting will be every section where perspective, experience, or original data should drive the content.
The information gain audit. Before editing, open the top five ranking pages for your keyword in separate tabs. Read them. Then read your AI draft and mark every paragraph that says something those five pages do not. If fewer than 30% of your paragraphs contain unique material, the piece is not ready for editing. It needs more: your data, your experience, your position.
The quality gate. The final check is not grammar or readability. It is a single question: if I removed my byline and published this anonymously, could a reader identify it as coming from someone who has done the thing being described? If the answer is no, the content lacks the Experience signal that Google's systems now weight heavily. Send it back for another pass.
One practical note on the quality gate: build it into the editorial calendar, not the editing pass. If the information gain audit happens at the editing stage, writers have already invested hours in a piece that may need to be substantially reworked. Move the audit earlier. After outlining and before drafting, confirm that the writer has at least three pieces of original material: a data point, a specific example, and a clear editorial position. If those three elements do not exist before the draft begins, the finished piece will not have them either.
This workflow is not efficient in the way that pure AI publishing is efficient. A team running it will produce fewer pieces per month. That is the point. The March 2026 core update demonstrated conclusively that volume without substance is not a content strategy. It is a liability that compounds with every page published.
The teams that will rank in 2026 and beyond are the ones that understood this before the update hit. The teams that are scrambling now are the ones that treated AI as a volume multiplier instead of what it is: a research and drafting tool that handles the 60% of content production that does not require original thought, freeing the creator to spend more time on the 40% that does.